Search Engine Scraping
Food And Beverage Industry Email Listhttps://t.co/8wDcegilTq pic.twitter.com/19oewJtXrn
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Content
Guide: Email Extractor And Search Engine Scraper By Creative Bear Tech
Then you should select the number of “threads per scraper“. You ought to actually only be using the “built-in web browser” if you're using a VPN similar to Nord VPN or Hide my Ass VPN (HMA VPN). The “Delay Request in Milliseconds” helps to maintain the scraping activity relatively “human” and helps to keep away from IP bans. The limitation with the area filters mentioned above is that not every website will necessarily contain your key phrases.
Full Tutorial Of Search Engine Scraper And Email Extractor By Creative Bear Tech
They are strictly created for revenue and are a type of spam. Besides stealing the content without giving credit where credit is due, scraping a Web website for information additionally skews the outcomes of the Search Engine Results Pages (SERPs). Search engines actually do wish to return essentially the most related outcomes when a question is made, however scraper sites principally pollute the search outcomes.
Blockchain and Cryptocurrency Email List for B2B Marketinghttps://t.co/FcfdYmSDWG
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Database of All Cryptocurrency Sites contains the websites, emails, addresses, phone numbers and social media links of practically all cryptocurrency sites including ICO, news sites. pic.twitter.com/WeHHpGCpcF
Important: Please Follow These Steps Before Running The Software
Another type of scraper will pull snippets and text from web sites that rank excessive for keywords they've targeted. This means they hope to rank extremely in the search engine results pages (SERPs), piggybacking on the original web page's page rank. Scraping search engines is an age-old tradition — at least as old because the internet. Because the major search engines have categorized the information in such a great way, a dialed in scrape can turn up millions of results for key phrases, URLs, and different metrics in a couple of hours. One possible cause might be that search engines like google like Google are getting nearly all their knowledge by scraping hundreds of thousands of public reachable websites, also without studying and accepting these phrases.
Allow The Website Scraper Through Windows Firewall
For instance, if you search for something on Bing or Google search engines like google and yahoo, you can go all the way as much as page 20 and even further. Usually, 200 outcomes/websites per keyword search are enough.
How To Run The Search Engine Scraper By Creative Bear Tech
Inside the software folder, instead of running the standard “CreativeBearTech.exe” file, you can run “CreativeBearTechManager.exe“. By working the CreativeBearTechManager.exefile, the search engine scraper will carry on working despite any crashes or errors. This feature will add plenty of armour to the search engine scraper and allow it to operate even in essentially the most opposed conditions.
A) Running The Creativebeartechmanager Exe File.
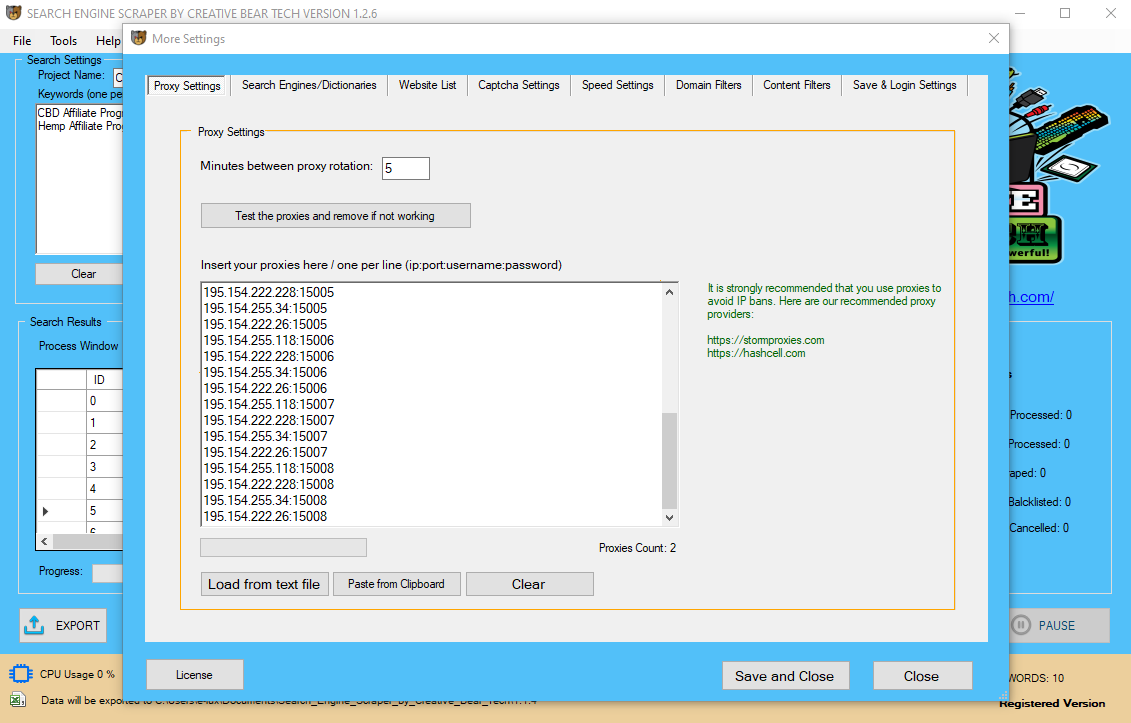
It is a Web site that steals content material, photographs, blogs and information for its personal monetary profit and creates a Web website of its personal with no thought of copyright infringement. Since the inception of Google AdSense and pay per click advertising, scraper sites have been significantly on the rise. Their major purpose is to attract site visitors and have users click on the scraper website’s paid ads, which in turn generates money for the owners/creators of the scraper websites. Most of the snippets of content that seem on these Web websites don't have any worth or use to the user. As the software program performs knowledge scraping inside browser windows, it will usually bring the browser home windows up and you would see the complete scraping course of in real time view. However, most people prefer to cover the browser home windows as they have an inclination to interfere with their work. Inside the Save and Login Settings tab, you could have the choice to add the login details in your Facebook account. On the primary GUI, click on on the “More Settings” option, then navigate to “Save & Login Settings“. You can run the software program in "Fast Mode" and configure the number of threads. For example, Google, Bing, Google Maps, etc are Sub Scrapers. Then you must select the variety of "threads per scraper". This means what number of key phrases you would like to course of on the identical time per website/source. For example, if I choose three sub scrapers and 2 threads per scraper, this is able to imply that the software would scrape Google, Bing and Google Maps at 2 key phrases per web site. Some provide little, if any materials or info, and are meant to acquire user information corresponding to e-mail addresses, to be targeted for spam e-mail. Price aggregation and shopping websites entry multiple listings of a product and allow a person to quickly evaluate the prices. GoogleScraper – A Python module to scrape completely different search engines like google and yahoo (like Google, Yandex, Bing, Duckduckgo, Baidu and others) by using proxies (socks4/5, http proxy). The device includes asynchronous networking help and is able to control actual browsers to mitigate detection. Before you leap into scraping UK B2B leads, it is important that you just learn this information for one of the best results. Our software program has an ability to also scrape e-mail addresses (which aren't provided by yell.com) by crawling websites. Let us give you a fast walk via via all of the configuration settings. If you have a fast internet connection or are operating the software on a VPS or a devoted server, check the "quick mode" option. The first possibility is the “Total number of search results (web sites) to parse per keyword“. You also have the choice to inform the software program “Maximum variety of emails to extract from the identical web site“. You even have the choice to “parse the search outcomes (websites) utilizing net browser” which just implies that the scraper will work at a single thread and it is possible for you to to view the reside scraping. Most scraper sites give the looks of a search engine outcomes web page or a directory. Scrapers often take sections of a Web site such as the title and outline of a page or would possibly even take an entire page and create a Web website or Web page of their very own. As talked about previously, the knowledge provided on a scraper website is not authentic and has little to no value to the person. You even have the option to "parse the search outcomes (websites) utilizing web browser" which simply signifies that the scraper will work at a single thread and you will be able to view the live scraping. You will be unable to use multi-threading options or disguise the browser. This possibility is good if you wish to see how the software works. The function of the content filter is to verify a website’s meta title, meta description and if you want, the html code and the visible body text. Click on “More Settings” on the main GUI and then click on the “Speed Settings” tab. A authorized case gained by Google towards Microsoft would possibly put their complete business as risk. Behaviour based detection is the most troublesome protection system. Enter your project name, key phrases and then select "Crawl and Scrape E-Mails from Search Engines" or "Scrape E-Mails out of your Website List". You can choose "Invisible Mode" if you do not want the software to open the browser windows.
- However, most individuals choose to cover the browser windows as they have a tendency to intervene with their work.
- Enter your project name, key phrases and then choose "Crawl and Scrape E-Mails from Search Engines" or "Scrape E-Mails out of your Website List".
- As the software performs data scraping inside browser home windows, it might usually bring the browser home windows up and you could see the complete scraping course of in actual time view.
- For instance, Google, Bing, Google Maps, etc are Sub Scrapers.
- You can run the software in "Fast Mode" and configure the number of threads.
- You can choose "Invisible Mode" if you don't want the software program to open the browser home windows.
Facebook requires you to be logged in to be able to view enterprise pages. You will need to add a Facebook account to your copy of the Yellow Pages Scraping Software to extend your success rate. The scraper will access your Facebook account from your native IP tackle on a single thread with human delays. It is price to level out from the start that UK Yellow Pages will need a lot of proxies because yell.com is quite temperamental and tends to ban IPs in a short time. You can use this UK Yellow Pages Scraper for extracting limitless B2B leads for your corporation. Enter your project name, keywords and then select “Crawl and Scrape E-Mails from Search Engines” or “Scrape E-Mails out of your Website List“. You can select “Invisible Mode” if you don't want the software to open the browser windows. You can run the software program in “Fast Mode” and configure the variety of threads. DO NOT RUN A VPN IN THE BACKGROUND WHILST USING A FACEBOOK ACCOUNT BECAUSE THIS WILL GET YOUR FACEBOOK ACCOUNT RESTRICTED. We suggest that you use loads of private devoted or even shared proxies. Generally, scraper sites are created particularly to put paid adverts on sites corresponding to Google AdSense. By default, the search engine scraper will scrape enterprise data from the website sources that you specify in the settings. This may embrace Google, Google Maps, Bing, LinkedIn, Yellow Pages, Yahoo, AOL and so forth. However, it's inevitable that some business records could Yelp Business Directory Scraper have missing data similar to a missing handle, telephone quantity, e mail or website. In the velocity settings, you possibly can select either toscrape Facebook in case emails not discovered on the target websiteORAlways scrape Facebook for extra emails. The extract emails that match the area name choice is really helpful if you solely wish to scrape business emails. This is especially useful for authorized compliance and privacy laws. A fast speed option was built-in for prime speed internet. The software program now saves the results for every city or state in separate information and likewise produce an amalgamated file with the outcomes for all areas for each keyword in one .csv file. The look of the scraper is far sleeker and extra streamlined. The Yellow Pages Scraper can now acquire all social media profiles by going to the web site of every business and extracting the social media urls. This mainly hides the reside preview pane to avoid wasting resources (CPU and RAM). If the app crashes, you'll be able to restart it and click on "full previous search" to resume from the last place. This is a special application that will automatically restart the scraper within the occasion that it closes unexpectedly.
Jewelry Stores Email List and Jewelry Contacts Directoryhttps://t.co/uOs2Hu2vWd
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Jewelry Stores Email List consists of contact details for virtually every jewellery store across all states in USA, UK, Europe, Australia, Middle East and Asia. pic.twitter.com/whSmsR6yaX
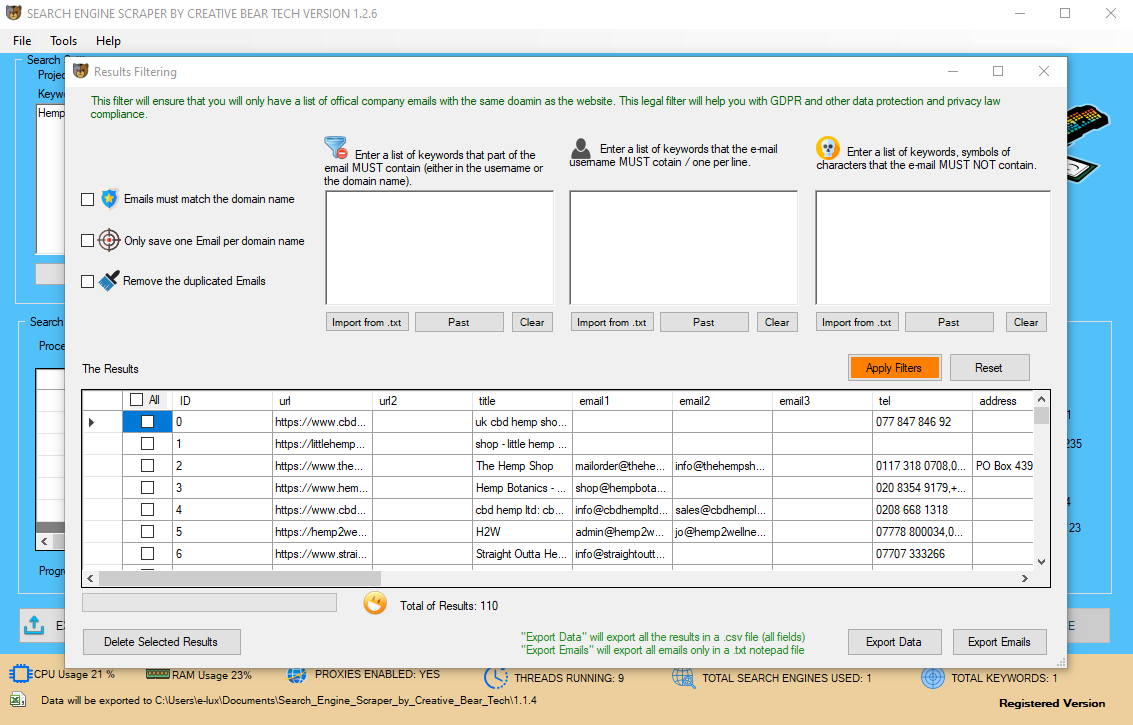
 So when you select to search the meta title, meta description and the html code and visible textual content for your keywords, the software program will scrape an internet site if it accommodates your keywords in both of the locations. It is beneficial that you just spend some time excited about your key phrases. You also needs to decide whether you want to use the domain filters and content material filters. This content material filter is what makes this email extractor and search engine scraper the most powerful scraping tool available on the market. Click on "More Settings" on the principle GUI and then click on on the "Speed Settings" tab. You even have the option to tell the software "Maximum number of emails to extract from the identical web site". Sometimes, an internet site could have a couple of e-mail handle (i.e. data@, hello@, gross sales@, and so on). This option is meant to save lots of time and processing power by not loading the pictures from web sites as these are not needed for our scraping endeavours.
So when you select to search the meta title, meta description and the html code and visible textual content for your keywords, the software program will scrape an internet site if it accommodates your keywords in both of the locations. It is beneficial that you just spend some time excited about your key phrases. You also needs to decide whether you want to use the domain filters and content material filters. This content material filter is what makes this email extractor and search engine scraper the most powerful scraping tool available on the market. Click on "More Settings" on the principle GUI and then click on on the "Speed Settings" tab. You even have the option to tell the software "Maximum number of emails to extract from the identical web site". Sometimes, an internet site could have a couple of e-mail handle (i.e. data@, hello@, gross sales@, and so on). This option is meant to save lots of time and processing power by not loading the pictures from web sites as these are not needed for our scraping endeavours.  So, the software program would concurrently scrape Google for two keywords, Bing for two key phrases and Google Maps for 2 keywords. You ought to actually solely be using the "integrated net browser" if you're using a VPN corresponding to Nord VPN or Hide my Ass VPN (HMA VPN). The "Delay Request in Milliseconds" helps to maintain the scraping activity relatively "human" and helps to keep away from IP bans. The software is not going to save information for websites that wouldn't have emails. Under this tab, it is possible for you to to set how deep the software program ought to scrape, which is able to influence on the scraping pace, hence the name. The first option is the "Total number of search results (websites) to parse per keyword". This just means what number of search results the software program ought to scrape per search. There are automated packages out there that send out bots to extract content material, reorganize it and create a new Web page. Some of those bots can scour 1000's of web sites in as little as an hour. Some of the software applications are programmed to implement “discover and exchange” for key phrases so the content would possibly seem totally different. Additionally, you can also get the software program to verify the body text and html code in your keywords as well. However, it will produce very expansive results which may be much less relevant. You also can inform the software to examine and scrape web sites that comprise a certain variety of your key phrases (you can specify it). The thought behind this content filter is that it'll solely scrape web sites that contain your keywords in the meta title and outline. Usually, all relevant websites will comprise your key phrases in the meta fields. The scraper will extract more business data in fast mode than it would otherwise. The "invisible mode" section will cover the browser inside which the scraping is taking place. It is really helpful that you just verify this option Data Extraction Software - Price Comparison & Reviews if you do not need for the browser to be operating in the background. You can use an built-in internet browser as a substitute of an http request. This should be your fallback choice in case the default http request mode isn't working correctly for you. Scrape and extract unlimited business contact particulars with our UK Yellow Pages Extractor. Our software will routinely extract business knowledge from yell.com together with emails, web sites, addresses, enterprise names, phone numbers and more. The scraper will auto save all files and allow you to scrape B2B leads on auto pilot. In this model, we have added an choice to add your Facebook account. When scraping each yellowpages.com (USA) and Yell.com (UK), the software program will attempt to harvest all of the available enterprise information instantly from the Yellow Pages business itemizing web page. Many occasions the advertisements on the page are the one relevant merchandise on the page for the user, as the hyperlinks to the entire other sites aren't what the consumer was looking for. Thus, the person clicks on the Google AdSense textual content link or affiliate link and the scraper yields a monetary return. Scrapers create these websites based on listings with high-site visitors snippets that contain key phrases with high exercise. These listings deliver traffic to the scraper web site, which in turn redirects the person to the site that the scraper has put collectively. The content material that's stolen usually has a high activity rely and isn't necessarily related to the ad, however since the exercise is high, the scraper site brings in the visitors. However, if the website scraper can not discover some contact data on the website, it'll proceed to verify LinkedIn, Facebook, Twitter and Instagram for the lacking contact details. LinkedIn and Facebook have a tendency to block/disallow entry to the corporate pages where all the data is stored, except a person is logged in. On the principle GUI, click on the "More Settings" possibility, then navigate to "Save & Login Settings". Go right down to the Accounts part and enter your login particulars. The software program will now use your login details to access Facebook and LinkedIn. A scraper web site is a web site that copies content material from different websites using net scraping. The content material is then mirrored with the goal of making revenue, normally through advertising and sometimes by promoting person information. Search engines such as Google might be considered a kind of scraper site. Search engines gather content from other websites, save it in their very own databases, index it and present the scraped content to their search engine's personal users. The majority of content scraped by search engines like google is copyrighted. For example, there are lots of manufacturers that don't necessarily comprise the keywords within the domain. The role of the content material filter is to verify a website's meta title, meta description and if you wish, the html code and the seen body textual content. By default, the software will only scan the meta title and meta description of each web site and verify whether it accommodates your keyword.
So, the software program would concurrently scrape Google for two keywords, Bing for two key phrases and Google Maps for 2 keywords. You ought to actually solely be using the "integrated net browser" if you're using a VPN corresponding to Nord VPN or Hide my Ass VPN (HMA VPN). The "Delay Request in Milliseconds" helps to maintain the scraping activity relatively "human" and helps to keep away from IP bans. The software is not going to save information for websites that wouldn't have emails. Under this tab, it is possible for you to to set how deep the software program ought to scrape, which is able to influence on the scraping pace, hence the name. The first option is the "Total number of search results (websites) to parse per keyword". This just means what number of search results the software program ought to scrape per search. There are automated packages out there that send out bots to extract content material, reorganize it and create a new Web page. Some of those bots can scour 1000's of web sites in as little as an hour. Some of the software applications are programmed to implement “discover and exchange” for key phrases so the content would possibly seem totally different. Additionally, you can also get the software program to verify the body text and html code in your keywords as well. However, it will produce very expansive results which may be much less relevant. You also can inform the software to examine and scrape web sites that comprise a certain variety of your key phrases (you can specify it). The thought behind this content filter is that it'll solely scrape web sites that contain your keywords in the meta title and outline. Usually, all relevant websites will comprise your key phrases in the meta fields. The scraper will extract more business data in fast mode than it would otherwise. The "invisible mode" section will cover the browser inside which the scraping is taking place. It is really helpful that you just verify this option Data Extraction Software - Price Comparison & Reviews if you do not need for the browser to be operating in the background. You can use an built-in internet browser as a substitute of an http request. This should be your fallback choice in case the default http request mode isn't working correctly for you. Scrape and extract unlimited business contact particulars with our UK Yellow Pages Extractor. Our software will routinely extract business knowledge from yell.com together with emails, web sites, addresses, enterprise names, phone numbers and more. The scraper will auto save all files and allow you to scrape B2B leads on auto pilot. In this model, we have added an choice to add your Facebook account. When scraping each yellowpages.com (USA) and Yell.com (UK), the software program will attempt to harvest all of the available enterprise information instantly from the Yellow Pages business itemizing web page. Many occasions the advertisements on the page are the one relevant merchandise on the page for the user, as the hyperlinks to the entire other sites aren't what the consumer was looking for. Thus, the person clicks on the Google AdSense textual content link or affiliate link and the scraper yields a monetary return. Scrapers create these websites based on listings with high-site visitors snippets that contain key phrases with high exercise. These listings deliver traffic to the scraper web site, which in turn redirects the person to the site that the scraper has put collectively. The content material that's stolen usually has a high activity rely and isn't necessarily related to the ad, however since the exercise is high, the scraper site brings in the visitors. However, if the website scraper can not discover some contact data on the website, it'll proceed to verify LinkedIn, Facebook, Twitter and Instagram for the lacking contact details. LinkedIn and Facebook have a tendency to block/disallow entry to the corporate pages where all the data is stored, except a person is logged in. On the principle GUI, click on the "More Settings" possibility, then navigate to "Save & Login Settings". Go right down to the Accounts part and enter your login particulars. The software program will now use your login details to access Facebook and LinkedIn. A scraper web site is a web site that copies content material from different websites using net scraping. The content material is then mirrored with the goal of making revenue, normally through advertising and sometimes by promoting person information. Search engines such as Google might be considered a kind of scraper site. Search engines gather content from other websites, save it in their very own databases, index it and present the scraped content to their search engine's personal users. The majority of content scraped by search engines like google is copyrighted. For example, there are lots of manufacturers that don't necessarily comprise the keywords within the domain. The role of the content material filter is to verify a website's meta title, meta description and if you wish, the html code and the seen body textual content. By default, the software will only scan the meta title and meta description of each web site and verify whether it accommodates your keyword.
A chilled out evening at our head offices in Wapping with quality CBD coconut tinctures and CBD gummies from JustCBD @justcbdstore @justcbd @justcbd_wholesale https://t.co/s1tfvS5e9y#cbd #cannabinoid #hemp #london pic.twitter.com/LaEB7wM4Vg
— Creative Bear Tech (@CreativeBearTec) January 25, 2020
Women's Clothing and Apparel Email Lists and Mailing Listshttps://t.co/IsftGMEFwv
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
women's dresses, shoes, accessories, nightwear, fashion designers, hats, swimwear, hosiery, tops, activewear, jackets pic.twitter.com/UKbsMKfktM